
Category: Collaboration
On to the Next Challenge
For over 3 and half years, I’ve been wrangling projects, pictures, and passions with the Smithsonian Transcription Center. I have been so fortunate to learn from and collaborate with an endlessly curious set of digital volunteers. Their commitment and generosity continues to inspire me (and astound me!). I’m grateful for the support of incredibly talented staff from across the Smithsonian Institution; I count myself lucky to have partnered with archivists, collections managers, digitization pros, librarians, social media managers, educators, researchers, interns, and directors. I want to thank them for their patience and kindness. They supported me while teaching me about their needs, standards, and aspirations.
I also wish to thank my colleagues in the Office of the Chief Information Officer for their dedicated support of systems and services that provided access to digital collections.
I’m further grateful to have worked with creative, funny, and talented teammates at Quotient, Inc. I have greatly enjoyed creating solutions and successes with you!
Finally, I want to thank colleagues who manage other crowdsourcing, citizen science, educational, digital humanities, and public engagement projects. As individuals and a whole, these people have modeled collegiality. Thanks to all of you for sharing what you learn and practicing what you preach.
I’m working on thanking all of the people above individually, but that will take me a while. Until then, please know that it has been my great pleasure to learn through conversation, observation, and collaboration – thank you!
♦ ♦ ♦
So what’s next?
I’m thrilled to share that I will be joining the Library of Congress in the National and International Outreach service unit and specifically, the National Digital Initiatives division.
Their work focuses on impact and possibility; I am looking forward to new challenges encompassing both and sharing along the way.
Volunpeers: Hashtag, Identity, & Collaborative Engagement

“Volunpeers” is a flexible term for volunteers, organizations, and institutions to succinctly represent the knowledge-building activities and collaborative enterprise in which they are engaged. When used as a hashtag, #volunpeers can be leveraged to quickly connect individuals to asynchronous collaborative activity. It is a term that may be used to draw novice volunteers into public discussion about crowdsourcing and citizen science activities, as well. It also may be used as a way to announce discoveries and call out for help. “Volunpeers” specifically challenges heirarchical, as well as the exclusivity of, knowledge production and the efforts to created that knowledge; as part of a wider set of activities, it is a term and an identity that may be affiliated with the promise of digital technologies, the internet, and the democratization of knowledge. It is also an identity adopted by participating volunteers to describe themselves and their positioning with this crowdsourcing project of the Smithsonian Transcription Center. This post describes the ways I first implemented the term in coordination with the activities of Smithsonian’s Digital Volunteers and the Smithsonian Transcription Center in April 2014 and its continued use today.
I was several months into my role as project coordinator for the Smithsonian Transcription Center in April 2014, plus a day or two into our second TC 7 Day Review Challenge. I’d issued a goal of reviewing–and ideally completing–as many pages as possible in 7 Days. It was an open, but still formidable task.
Digital volunteers at this point tended to communicate directly with the Transcription Center (i.e. me) via feedback e-mails and tweets. The TC did not and still does not have a discussion board. One drawback of this design decision: some kind of work-around might be necessary when volunteers wanted to bounce ideas or ask others to join them on challenging projects. However, it is also a design decision that creates alternative opportunities for communication between participants – specifically in the social media spaces in which they may already operate.
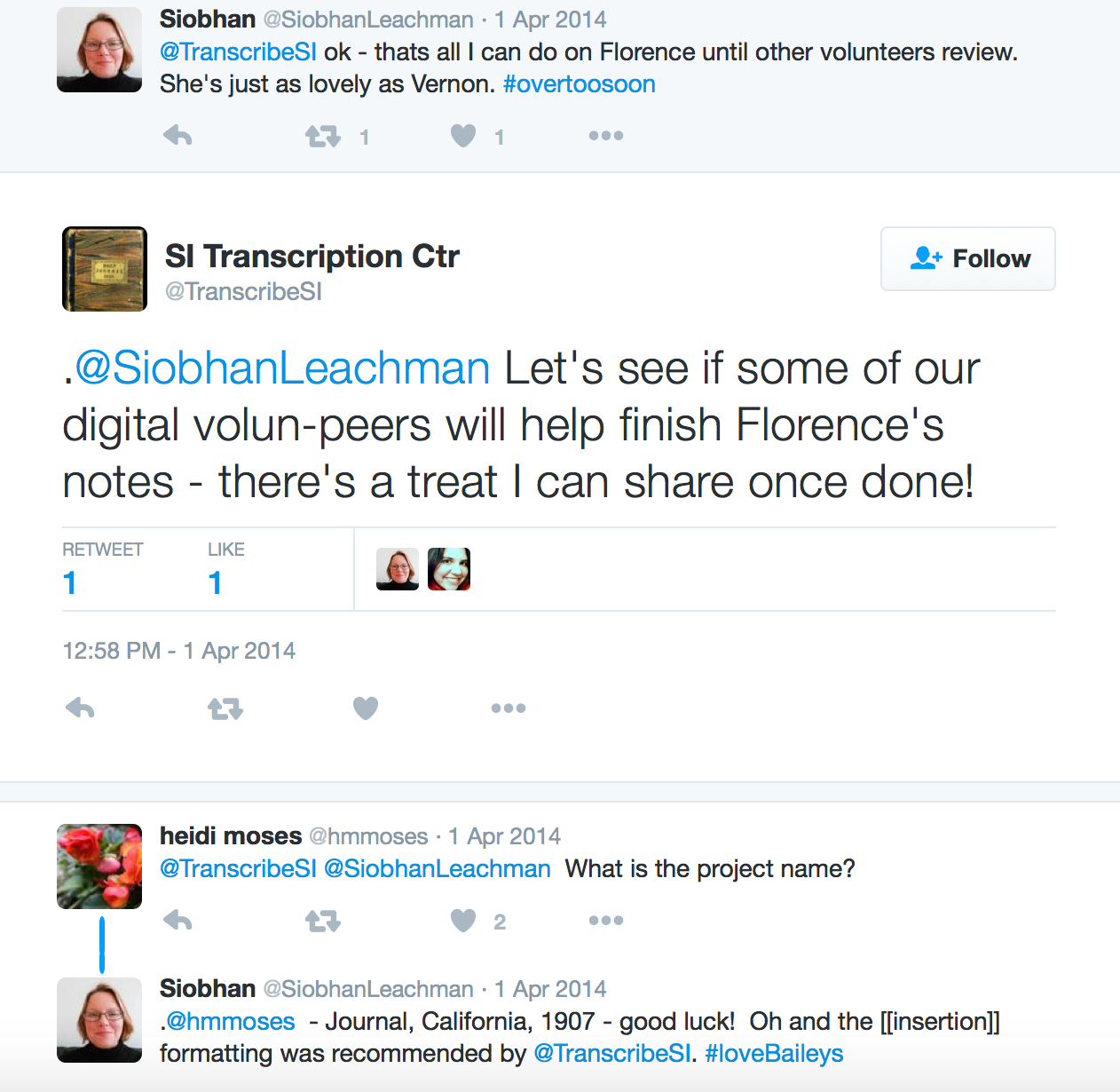
While responding to a volunteer’s tweets on 01 April 2014 using the @TranscribeSI Twitter handle, I suggested another “volun-peer” might be able to help. In the first 2 days of using these 9 characters, I swiftly incorporated the term “volun-peer”, then “volunpeer”, then the hashtag #volunpeers into the rhetorical approach and central mindset of the TC in three key ways.
In the first use of the hyphenated term, I’m suggesting a portmanteau to blend of meaning of volunteer and peer. This implicitly rejects a hierarchy of volunteers and highlights the peer review and collaboration of the TC.
In the second use, I’m still applying a hyphen but signalling members of the group to an unknown wider set of members while setting out a call-to-action.

In the third use, I continue to use the hyphenated term and this time attempt to catalyze a call to action focused around content: a dapper Leo Baekeland and his diaries.
I actually start using a hashtag and non-hyphenated term in the fourth use of volunpeers on 03 April 2014. This first time the hashtag term is singular: #volunpeer. I used it in this way to share the collective contributions of all volunteers engaging with the 7 Day Review Challenge.
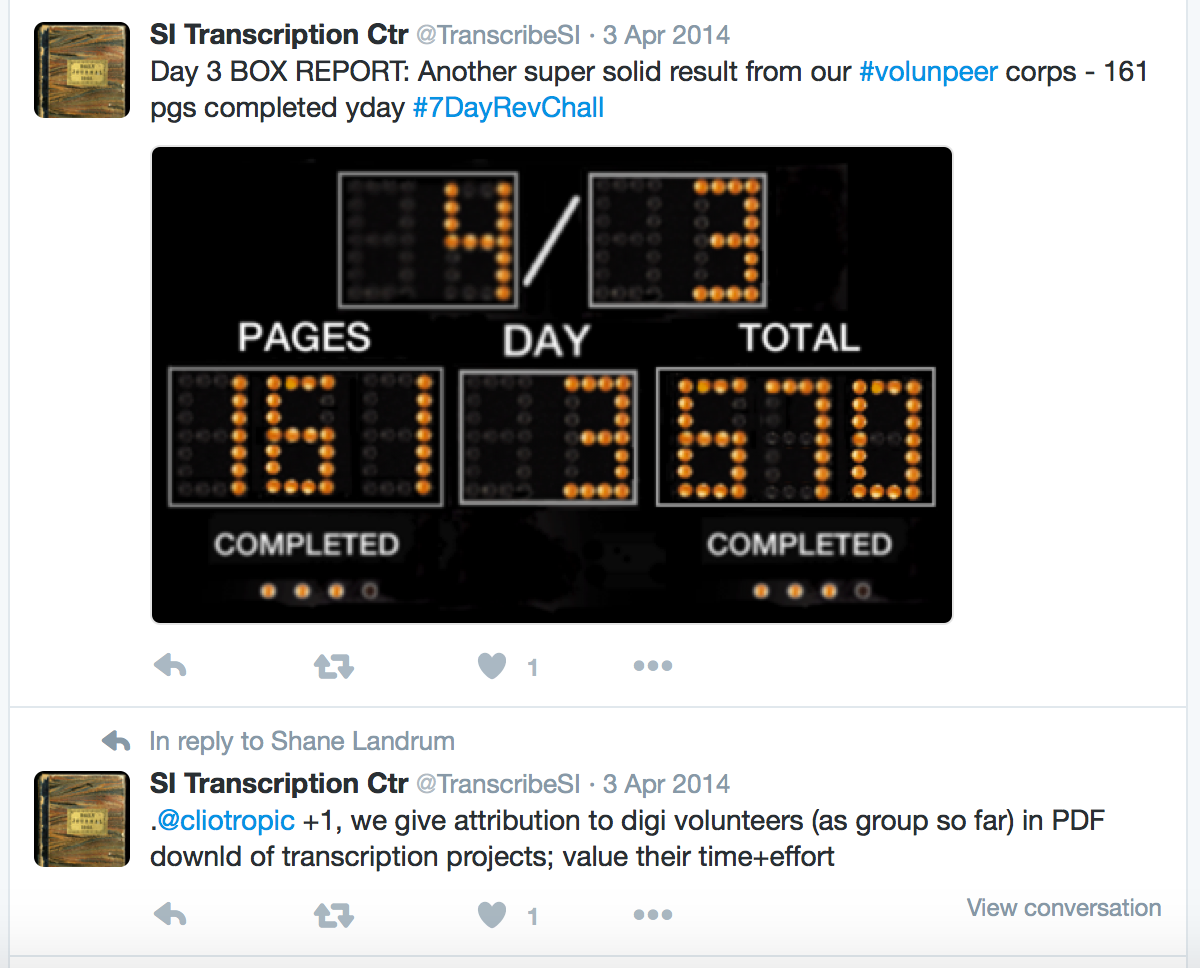
Finally, in the 5th use of the term the next day, I use the plural hashtag. In this case, I’m asking questions and trying to generate genuine discussion using this hashtag.
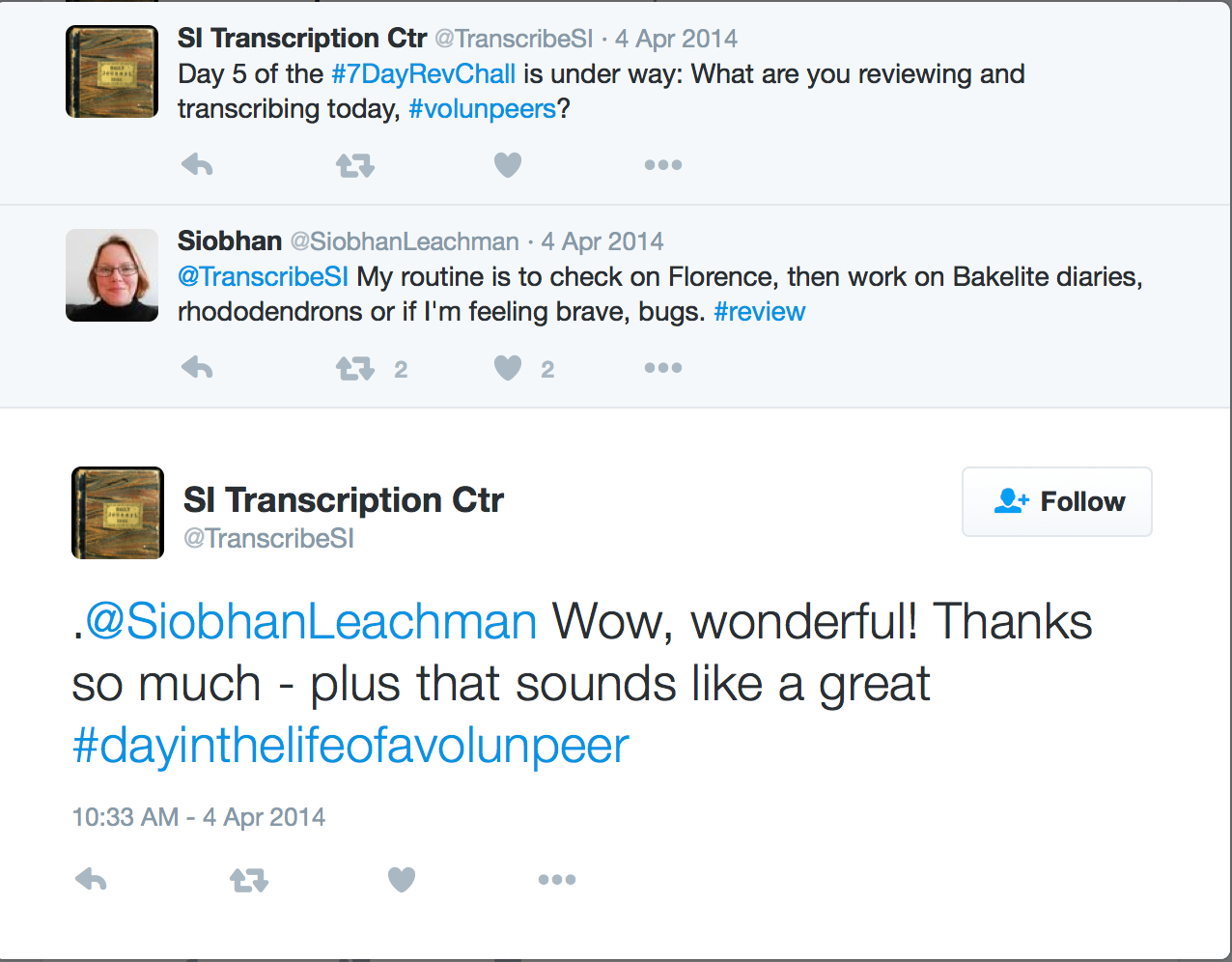
By the 6th, 7th, and 8th uses, the hashtag is allowing me to attach to it messages of encouragement, questions, and report outs. This Grand Total summary below is my 7th use of the term “volunpeers”.
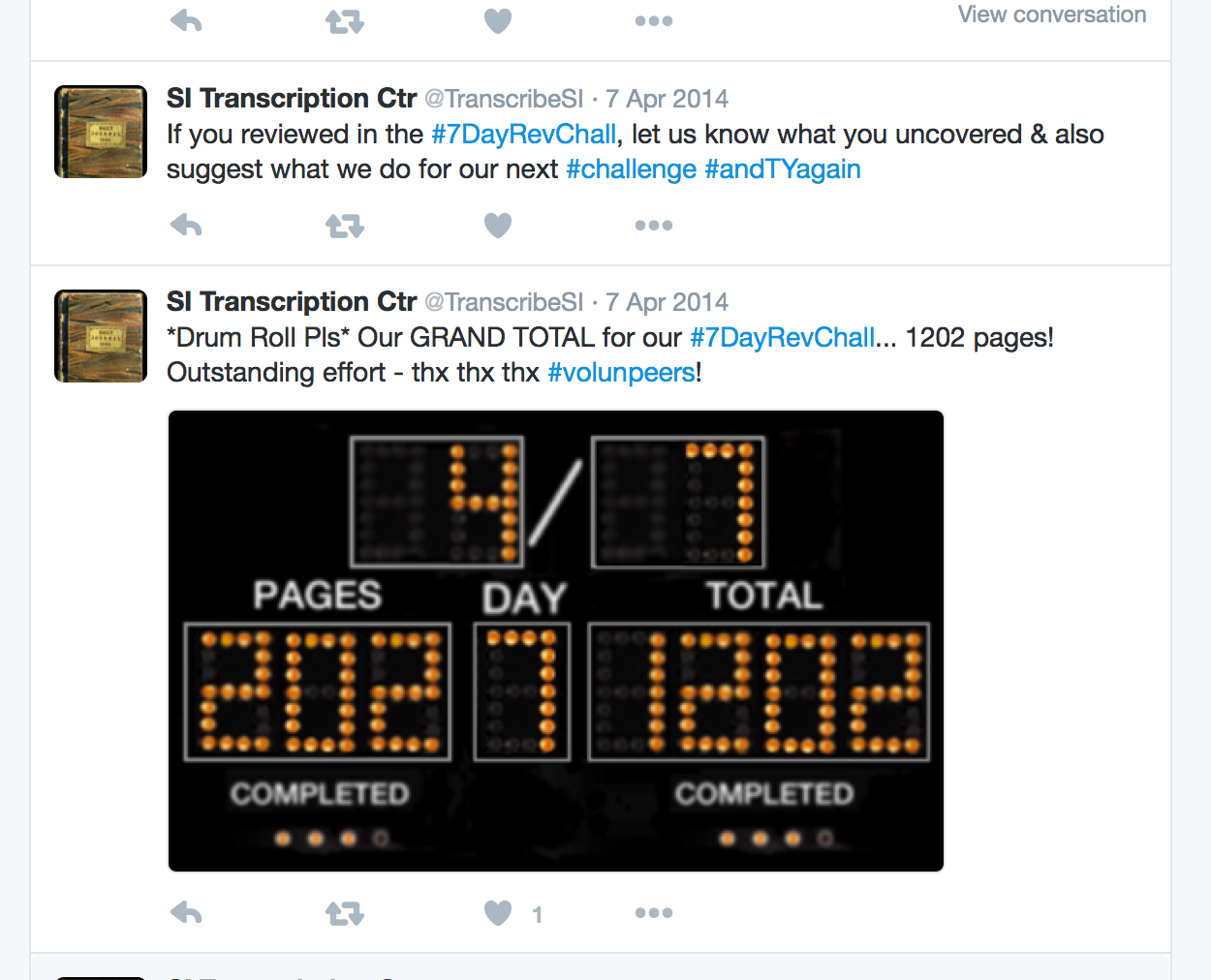
I’m also able by 07 April 2014 to leverage the structural capacity it affords and its discoverability as a hashtag (c.f. Mechant & De Marez, 2012).
In a forthcoming article in a volume of COLLECTIONS: A Journal for Museums and Archives professionals, I describe the ways a hashtag can be a useful string of characters, plus so much more. Specifically, as a hashtag, #volunpeers is employed as a vehicle for conveying information through a social network to the eyes of other willing and interested volunteers.
To summarize myself: the term #volunpeers moves beyond an ascribed label to an adopted identity for those who feel affinity toward its meanings. It also actively incorporates collaborative construction of knowledge. Using #volunpeers chips at barriers and hierarchies of authority between an institution and public through on-going interaction. Staff are learning and improving their workflows through interaction with the public, as well. Rather than telling and directing, #volunpeers can be deployed by the public as well as staff as a means of sharing and inviting productive discussion and inclusion with their work. I use the term to signify the boundaries and the ways they might be blurring, as with collaborative space that uses peer review; and to honor what is possible together rather than what is being done by individuals.
I should note that while @TranscribeSI was the first to use the hashtag #volunpeers, it was used several times in 2013 by a PeerCoin community; and specifically to signal knowledge exchange!
So, what do you make of “volunpeers”? What does it mean to you? Do you think #volunpeers is appropriate, ambitious, or too conservative for crowdsourcing and citizen sceince? Do you consider yourself a volunpeer and if so, why?
Mechant, Peter, and Lieven De Marez. 2012. “Studying Web 2.0 Interactivity: A Research Framework and Two Case Studies.” International Journal of Interactive Communication Systems and Technologies (IJICST) 2, no. 2: 1-18.
Dreamy Digital Engagement at SXSW Interactive

At SXSW Interactive, I was on the trail of engagement, interaction, communication, and online collaboration – from opening sessions to my crowdsourcing panel on 12 March and beyond.
In November 2015, I was frankly pumped to have my panel on building engaged communities through crowdsourced transcription accepted for SXSW Interactive. The panel we submitted included three forward-thinking, complimentary mindsets with unique views into the challenges and complexities of crowdsourcing: digital curator Dr. Mia Ridge and independent software developer Ben Brumfield and long-time Citizen Scientist and self-identified #volunpeer Siobhan Leachman.
 When March 2016 arrived, I was well past thrilled – but also focused on making our panel useful and engaging, even as we discussed approaches for engagement. We arranged our session as a brief introductory round robin, a series of discussion prompts, and open discussion – finalized over pretty delicious brats and brews at Easy Tiger. Mmm, “brain food.” We also gathered useful resources for getting up to speed on our discussion and shared them along with our panel slides.
When March 2016 arrived, I was well past thrilled – but also focused on making our panel useful and engaging, even as we discussed approaches for engagement. We arranged our session as a brief introductory round robin, a series of discussion prompts, and open discussion – finalized over pretty delicious brats and brews at Easy Tiger. Mmm, “brain food.” We also gathered useful resources for getting up to speed on our discussion and shared them along with our panel slides.
On Saturday, March 12, during our standing-room only session, we had observations and direct questions with a practical bent. Specifically we heard questions about tried-and-true tactics for recruiting and retaining participants (lifecycle of participants). We were able to reflect on our approaches, as well as what we might do as best practice. We were also asked about the ways crowdsourcing can be integrated as more of a “win” such as being acknowledged as a credited volunteer contribution. We also were asked what we viewed on the horizon for crowdsourcing. Mia is concerned with machine learning and leveling up human computation, Siobhan is most interested in the connections between the data, while Ben is focused on the mobile writing on the wall. I’m interested in all of those things, but also maintaining supportive spaces + using the data + new tasks such as audio transcription and image-based decision trees (for the TC). Finally we also had queries about the potential to integrate crowdsourcing into the classroom. We offered smaller examples of integration in secondary and primary schools, as well as with regard to life-long learning. Siobhan rounded up the commentary in this storify.
As I wrote elsewhere in our bid for selection: “The most important element of our panel is passion – it will become clear to you if when we’re selected that we aren’t merely advocates for the power of many hands making light work. Rather we want to make those tools, projects, and experiences the very best they can be. We also support openly sharing best practice and the product whenever possible.” It was a pleasure to convene with Siobhan, Ben, and Mia. Check in with Mia’s round up of our panel at SXSW.
Are you thinking about what’s next for crowdsourcing? Join us in Krakow at DH2016 on 12 June to sight the terrain that lies ahead for crowdsourcing. You can apply and learn more about our goals for a collaborative session here.
Watch this space for my round up of the rest of the sessions I attended at SXSW: including but not limited to”posts that disappear,” seeding entrepreneurial cities, misguided understandings of participation barriers.
Featured Image via Mike Killi’s tweet – thanks for spending the session with us, Mike!
Many Publics, Better Models, & Engaging Volunpeers
For her Nieman Lab fellowship, Melody Kramer interviewed me about my approach to volunteers and community with the Smithsonian Transcription Center.
In her resulting report “Putting the Public into Public Media,” Melody culls insights shared from contexts of many public(inter)facing projects. She puts forth alternative and manageable models for membership. For me, the take-away is to build from a simple but not-so-easy to achieve starting point: ask your public(s) to build with you, have a say in the product they consume, and work with your product to better suit their needs. Together, you can attain more meaningful, deeper, and resilient engagement.
Melody features my approach with the Smithsonian Transcription Center as a case study. In addition, she’s included some of my comments as a footnote. She asked me to detail “how” I build community and engage with our volunteers. Continue reading for my answers to Melody’s question: “How do you foster community?”
“I think I have fostered community by
- being authentic in my engagement (using my voice not hiding behind the Smithsonian, and being enthusiastic because this stuff is pretty cool),
- asking questions that furthered the dialogue (how did you hear about us? what did you think of that? what was most surprising? what would you like to do next?)
- establishing a rhetorical approach that made it clear that we/I was learning at the same time as the volunteers
- establishing a rhetorical approach that suggests there is ALWAYS more to the story and that this is a chance to make discoveries – and then by recognizing or acknowledging those discoveries
- creating the hashtag #volunpeers to allow volunteers to leverage the structure of social media spaces to communicate with one another and with me/us – encouraging them to use it as well to ask for help or indicate a project needs review, etc
- creating collaborative competitions, rather than leaderboarding: #7DayRevChall (7 Day review challenges) allowed people to contribute collectively to a goal, then metric and try to beat the group goal – and using daily updates to share progress. This also allows for skills acquisition and learning best practice for review AND addresses an issue we see frequently – folks love transcribing and pages languish waiting for review. Every 2 months, we draw attention to this
- focusing on the process of transcribing and reviewing often over the volume of the product – and cultivating/encouraging patience from experienced volunteers in regard to “newbies”
- letting volunteers speak to each other directly in spaces in which they already live and are comfortable (Twitter, Facebook, Tumblr) – and we have benefitted from volunteers who are welcoming and want to help each other complete projects
- Also by engaging through those 3 social media networks (also instagram some and hopefully reddit soon), volunteers have the ability to “curate” and own their experience and the product they have created. My perception is that creates more in-depth brand engagement, as well – these volunteers list “digital volunteer for @TranscribeSI” or “#volunpeer for @TranscribeSI” in their bios
- listening to the feedback and description of external interests from volunteers and gauging their excitement in subject matter – then actively courting the archives, museums, and libraries that have related material
- Finally, actually integrating their feedback into site design when(ever) possible”
It seems to me that many of these steps start with two words: curiosity and sharing. In practice, these two words create a cycle of behavior – as you’re curious, you investigate. When you discover, you may want to share so others can learn. When others share, your interests are piqued and you become … more curious. Asking questions, discovering connections, solving challenges, and bringing together people – these all emerge as actions grounded in curiosity and sharing. When I understand that a volunteer has had a lightbulb moment with a project, I try to connect them and this experience to the Smithsonian group that has shared the project. Then staff and public alike are experiencing the moment of discovery – and learning from each other in the process. This often happens in our social media spaces, but I also do this one-on-one with feedback e-mails and questions from our volunteers.
Are you a community manager or are you a volunteer for an organization? How do these approaches relate to your experiences?
Three Challenges to Scholarly Crowdsourcing
I spoke about three challenges in scholarly crowdsourcing in a CCLA panel discussion on 07 May 2015. Here is what I had to say about trust, workflow, and acknowledgement.
I was invited to participate in the CCLA workshop on scholarly crowdsourcing – hosted by the University of Maryland and Drs. Mary Flanagan, Neil Fraistat, and Andrea Wiggins. I was asked to join a panel discussion and share my thoughts on challenges for scholarly crowdsourcing. Here are my notes in full.
When I think about scholarly crowdsourcing, I start with possibilities – the distributed, collaborative, unexpected connection that inevitably occurs. I know these possibilities to be true from my practical work and research: expanding discussion with crowds who are focused on achieving shared goals. Stemming from this work and learning, I see three challenges for scholarly crowdsourcing. These challenges can impact practice, policy, and participation; they are trust, workflow (a.k.a. resources) and acknowledgement.
TRUST
I believe people understand their worlds through cumulative experience and bundle that with them wherever they go. That means everyone brings baggage on these adventures – sometimes that makes collaborating a bit longer to sort out… But sometimes that baggage is like Mary Poppins’ carpet bag – providing what is needed in an enchanted moment of engagement. Without trust in the potential of the product and in the well-meaning nature of the community, we might not tap into hidden reservoirs of skill and knowledge.
That calls us to trust the process of connecting with people who have useful knowledge and skill sets. It asks us to trust that quality data can be produced by a truly motley crew – and to grapple with the potential of that crowd-generated information to paint a more complete picture than presented by an expert.
We have seen the results and we are bought in, to varying degrees, in this room and on the stream – but how can we make this a cultural shift to trust, so our starting point is no longer justifying quality but rather showcasing possibility?
Trust is Risky.
Trust changes design elements – for example, decreasing single key entry standards from 10 to 3. Trust is shaped by and reflected in discourse, rhetorical approaches, and instructions – these words+images+workflows can create or flatten barriers to entry.
Trust makes authentic communication and opportunity possible by — at least in small ways — becoming (temporarily) vulnerable. Trust is a vital component of successful public engagement – and it remains challenging.
WORKFLOW
The reality of crowdsourcing typically is born from the need for help – whether in expertise or scale.
I frequently find workflow concerns at the foreground of managing projects. It is one of the most underdeveloped (perhaps underrated) elements of crowdsourcing projects. I think we can address this challenge by listening closely to those managing projects and considering creatively solutions.
We can return to our designs and find ways to make them better… indeed, some of us never leave the design phase as we iterate and optimize experiences. We can also break down the processing of data and the crowdsourcing experience into small and manageable YET still connected and coherent steps. We must develop trust in new ways of “doing” as well – to be innovatively practical in rethinking resource constraints and workflow demands.
ACKNOWLEDGEMENT
The final challenge I see is acknowledgement – in many ways, for participants, organization, and voices yet to join.
Acknowledgement is honoring the organization/ institution/ or project’s side of the bargain, whether reporting on outcomes or making products more available – to articulate through action: “we are doing our part as you do your part”
Acknowledgement is more than high-fiving or virtually fête-ing the crowd – though that is an extremely important part of the practice. It is building that acknowledgement into the system – such as noting crowdsourcing efforts in newly created collections records.
We must face the challenging pieces of acknowledgement, such as respecting the community’s new knowledge enough to give them a place to apply that knowledge – evolving the activities or tasks in which they can participate.
Maybe acknowledgement is making the product available in new ways, with less restriction (trust again!), and opening the process with interoperability in mind.
And still acknowledgement requires investment – being there, listening, thoughtful development and design, open communication, and a willingness to go a few extra steps to demonstrate what crowdsourced public engagement means.
Acknowledgement is also reflecting on who is NOT present, who is not yet participating, and taking clear steps to improve access at every level and to increase representation – to surface and tell stories that have been left behind, erased, or blurred.
Those are the challenges I see in scholarly crowdsourcing – and I hope the conversations we have today lead to discussions we hold elsewhere and practical steps to make these obstacles into opportunities for better experiences from every angle.